AI 的任务是设计 Agent 程序,目标是实现把 感知信息 映射到 行动 的 Agent 函数
Agent 和环境
Agent 通过 传感器 感知环境,并且通过 执行器 对所处环境产生影响。如下图所示:
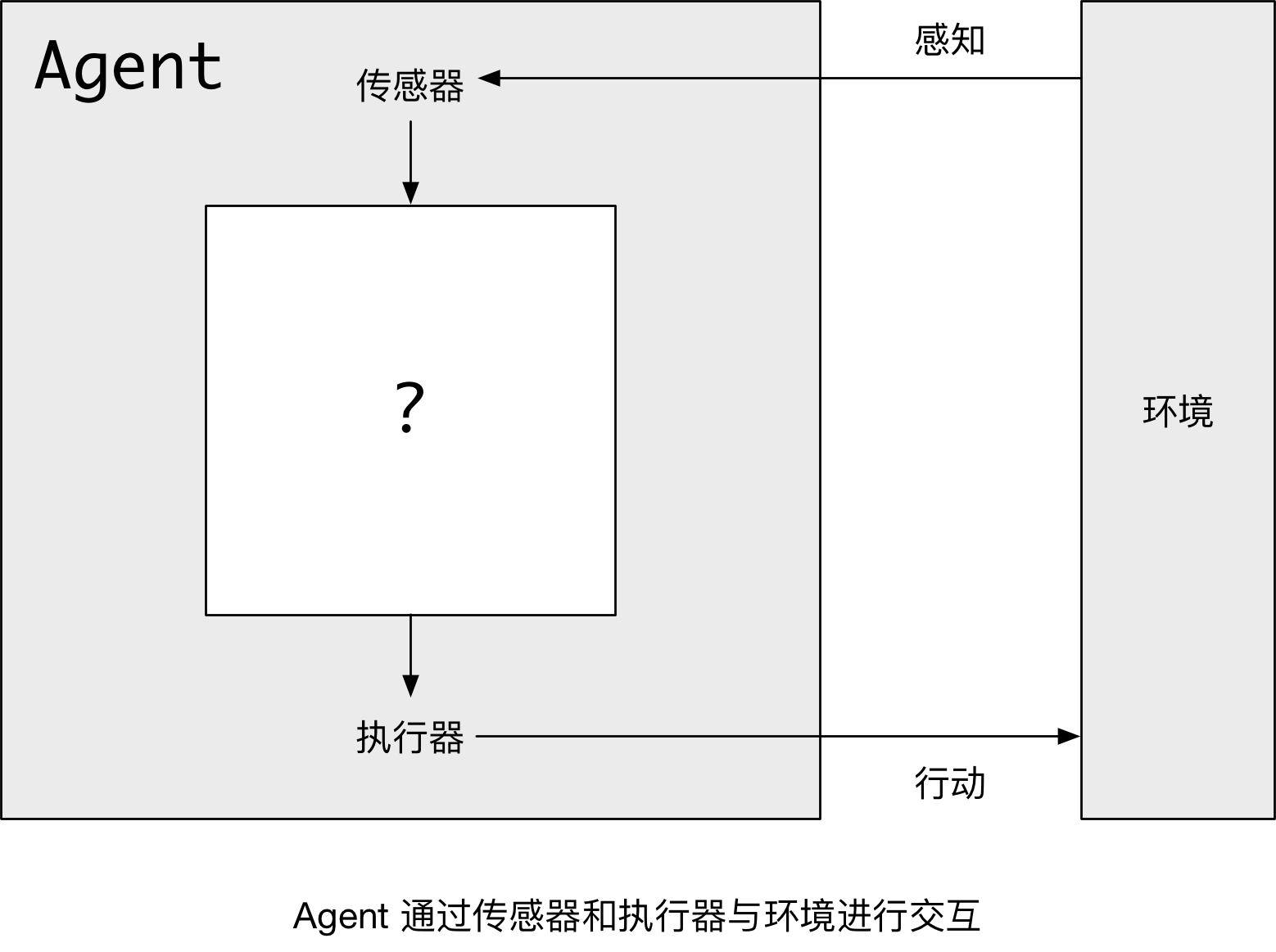
类比一下:
- 人类 Agent 用眼睛、耳朵等器官 感知 环境,用手、脚执行动作 影响 环境;
- 软件 Agent 可以接收键盘输入、文件内容和网络数据包作为 传感器 输入,可以用屏幕显示、写入文件和发送网络数据包作为 执行器 来影响环境。
其中:
- 我们用 感知 来表示任何 给定时刻 Agent 的感知输入
- Agent 的 感知序列 是该 Agent 所收到的 所有输入数据 的完整历史
- Agent 在任何时刻的 行动选择,依赖于到该时刻为止,Agent 的整个感知序列
从数学角度而言,Agent 函数 描述了 Agent 的行为,可以将 任何给定的感知序列映射为行为
好的行为——理性的 Agent
理性的 Agent 是做事正确得 Agent
- 当把 Agent 置于一个环境后,Agent 会针对收到的感知信息,生成一个行动序列
- 而这个行动序列又会导致环境经历一系列的状态变化
如果该系列正是我们 期望 的,那么这个 Agent 的性能良好!
注意:要以 性能度量 针对 环境状态 进行 评估,以判定 Agent 的行动是否是我们期望的!
理性 的判断依赖以下 4 个方面:
- 定义成功标准的性能度量
- Agent 对环境的先验知识
- Agent 可以完成的行动
- Agent 截止到此时的感知序列
由此,我们可以推导出 理性 Agent 的定义:
对每一个可能的感知序列,根据已知的感知序列提供的证据和 Agent 具有的先验知识,理性 Agent 应该选择能 使其性能度量最大化的行动。
全知、学习和自主性
一个 全知 的 Agent 明确地知道它的行动产生的实际结果,并且做出相应的动作,但在现实中,全知者是不可能的!
因此,对于理性的定义并不要求 全知,理性的选择只依赖于当前为止的感知序列。同时还要确保,不要因为疏忽,让 Agent 做出愚蠢的行动。
理性的 Agent 不仅仅能够收集信息,而且还能够从感知的信息中 尽可能的学习。
- Agent 最初的设定,可能反应的是环境的先验知识
- 随着 Agent 经验的丰富,这些知识会被增加或者改变
如果,Agent 只依赖于设计人员的先验知识,而不是自身的感知信息,我们会说这个 Agent 缺乏自主性,理性的 Agent 应该是自主的 —— 通过学习,弥补不完整的或者不正确的先验知识。
在实践中,很少要求 Agent 从一开始就完全自主,当 Agent 没有或者只有很少的经验时,它的行为往往是随机的,除非设计人员提供一些帮助。因此给人工智能的 Agent 提供一些初始的知识以及学习能力是合理的。当得到关于环境的充足经验后,理性 Agent 的行为才能独立于它的先验知识有效地行动。
与学习向结合,使得我们可以设计在很多不同环境下,都能成功的理性 Agent。
任务环境
任务环境 就是 理性 Agent 要“求解”的 基本问题
在设计 Agent 时,第一步就是 尽可能、完整、详细地说明任务环境。
而 PEAS 描述 就是以表格的方式,详尽地列举出任务环境的:性能(Performance)、环境(Environment)、执行器(Actuators) 和 传感器(Sensors) 的相关内容。以 自动驾驶的 Agent 为例,如下表所示:
| Agent 类型 | 性能 | 环境 | 执行器 | 传感器 |
|---|---|---|---|---|
| 自动驾驶 |
|
|
|
|
任务环境的性质
人工智能领域中任务环境的范围是非常大的,但是,我们可以定义数量相对少的维度对任务环境进行分类。在此,先简单罗列一下这些维度,后续会详细展开:
- 完全可观察 和 部分可观察
- 如果传感器在每个时间节点上,都能获得环境的完整状态,那么这个任务环境是完全可观察的
- 如果传感器能够检测所有与行动决策相关的信息,那么这个任务环境是有效完全可观察的
- 单 Agent 和 多 Agent
- 独自玩字谜游戏 的 Agent 处于单 Agent 环境,而 下棋游戏 的 Agent 则处于双 Agent 环境
- 区别的关键点在于:一个 Agent 是否要把另外一个对象 —— 当做 Agent 看待
- 下棋 是 竞争性 的多 Agent 环境,驾驶 是 部分合作 的多 Agent 环境
- 确定的 和 随机的
- 如果环境的下一个状态,完全取决于当前状态和 Agent 执行的动作,那么这个任务环境是确定的
- 原则上说,Agent 在完全可观察的、确定的环境中,不需要考虑不确定性
- 随机的 任务环境指的是:虽然后果不确定,但是可以 通过概率进行量化
- 片段式的 和 延续式的
- 在片段式环境中,每个片段中 Agent 感知信息并完成 单个 行动,并且 后续片段不依赖于之前的片段中采取的行动
- 在延续式环境中,当前决策会影响到未来所有的决策
- 静态的 和 动态的
- 不随时间变化的任务环境是静态的
- Agent 计算时,需要考虑时间变化的任务环境是动态的
- 离散的 和 连续的
- 环境的状态、时间的处理方式以及 Agent 的感知信息和行动,都有离散、连续之分
- 已知的 和 未知的
- 严格地说,这种区分指的不是环境本身,而指的是 Agent(或者设计人员)的知识状态
- 在已知的环境中,所有行动的后果是给定的,或者可以通过概率统计
- 在未知的环境中,Agent 需要学习环境是如何工作的,以便做出好的决策
Agent 程序
AI 的任务是设计 Agent 程序,目标是实现把 感知信息 映射到 行动 的 Agent 函数。Agent 程序可以具有统一的框架,即:
- 输入:是从传感器得到的当前感知信息
- 返回:执行器的行动抉择
注意:
- Agent 函数是以整个感知历史作为输入的
- Agent 程序只是把当前感知作为输入,因为无法从环境中获得更多信息
- 如果 Agent 的行为要依赖整个感知序列,则需要记住所有感知信息
从类别上,可以把 Agent 程序分为以下四种,分别是:
- 简单反射 Agent
- 基于模型的反射 Agent
- 基于目标的 Agent
- 基于效用的 Agent
学习 Agent
所有 Agent 都可以通过 学习 改造自身的性能!
下图是学习 Agent 的通用模型:
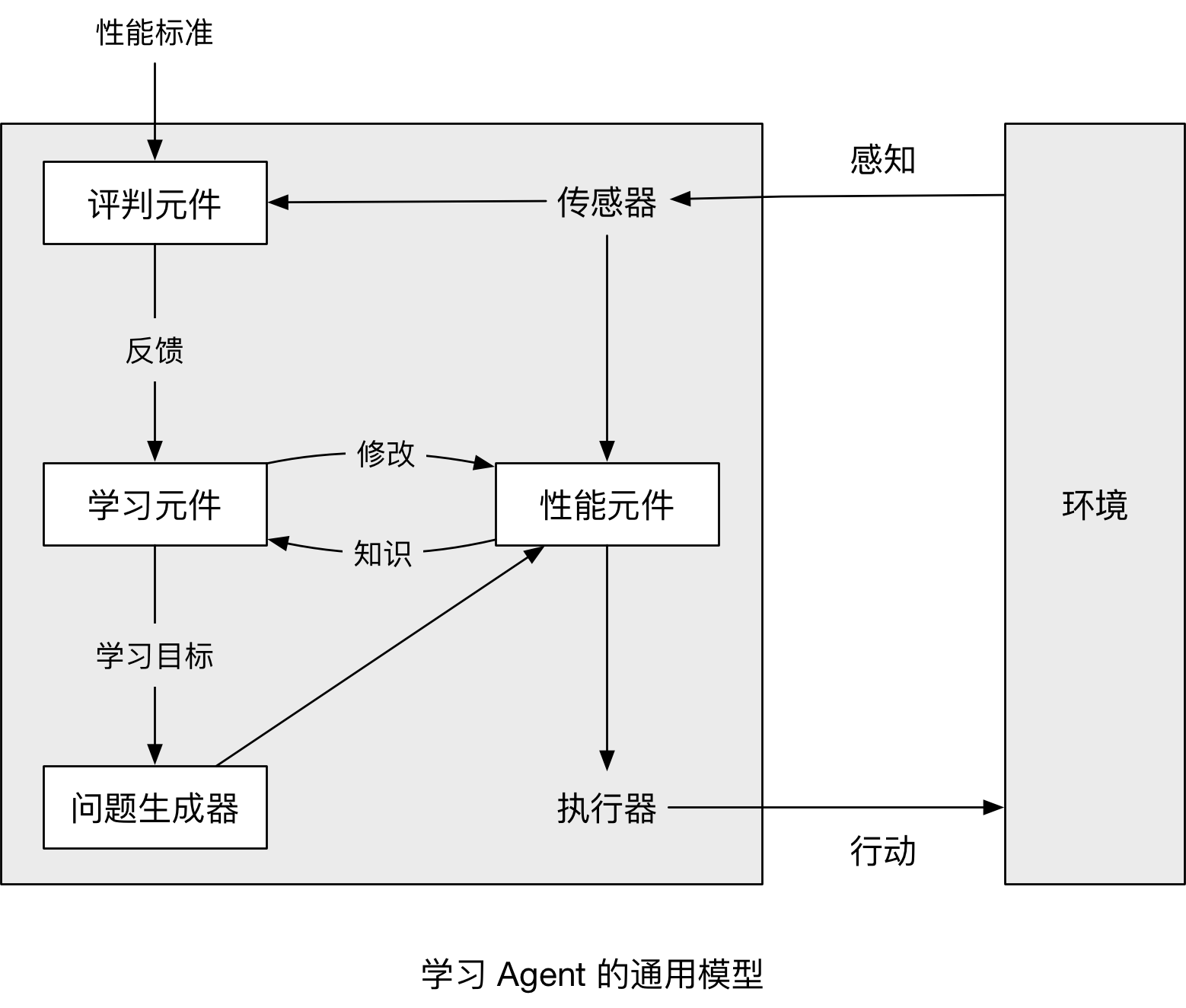
其中:
- 性能元件 是之前介绍的整个 Agent,负责接收感知信息并作出决策
- 学习元件 利用 评判元件 的反馈,来 评判 Agent 做的效果,并确定应该如何 修改性能元件 以便将来做的更好
- 评判元件 根据固定的性能标准,告诉 学习元件 Agent 的运转情况
- 问题生成器 负责提出行动建议
一句话小结
AI 的任务是设计 Agent 程序 —— 感知环境并且行动;Agent 的行为表现是可以度量的;Agent 可以通过学习改进性能的。